Обзор конференции «Velocity 2018»
Введение
Velocity — это конференция, которая посвящена распределённым системам. Её организует издательство O’Reilly и она проходит трижды в год: один раз в Калифорнии, один раз в Нью-Йорке и один раз в Европе (причём город меняется каждый год).
В 2018 году она проходила в Лондоне с 30 октября по 2 ноября. Её устройство несколько сложнее, чем то, с чем я сталкивался на российских конференциях. Кроме достаточно привычных двух дней докладов тут было еще два дня тренингов, который можно брать полностью, частично или не брать совсем. Всё вместе это превращается с серьёзный квест по выбору типа нужного билета.
Общее впечатление от конференции: авторы очень хорошо выступают (а keynote сессии — это целое шоу с представлением спикеров и их выходом на сцену под музыку), но при этом мне попалось мало докладов, которые были бы глубокими именно с технической точки зрения.
Самая “горячая” тема этой конференции - Kubernetes, который упоминается чуть ли не в каждом втором докладе.
Очень хорошо выстроена работа с соцсетями: в официальном twitter-аккаунте во время конференции было очень много оперативных ретвитов с материалами докладов. Это позволяло бегло посмотреть, что происходит в других залах.
В этом обзоре я расскажу про те доклады и мастер-классы, которые мне запомнились. К некоторым докладам я прикладываю ссылки на дополнительные материалы. Частично это материалы, на которые ссылались авторы, а частично материалы для дальнейшего изучения, которые я нашёл сам.
Мастер-классы
31 октября - это был день, когда докладов не было, но происходило 6 или 8 мастер-классов по 3 часа чистого времени каждый, из которых нужно было выбрать два.
P.S. В оригинале они называются tutorial, но мне кажется правильным перевести их как “мастер-класс”.
Chaos Engineering Bootcamp
| Ведущий: Ana Medina, инженер в компании Gremlin | Описание |
Мастер-класс был посвящён введению в chaos engineering. Ана бегло рассказала что это такое, какую пользу приносит, продемонстрировала, как его можно использовать, какое ПО может помочь и как начать использовать его в компании.
В целом, это было хорошее введение для начинающих, но мне не очень понравилась практическая часть, которая представляла собой развёртывание демонстрационного web-приложения в кластере из нескольких машин с помощью Kubernetes и прикручивания к нему мониторинга от DataDog. Главная проблема с ней заключалась в том, что мы на это потратили почти половину времени мастер-класса и это было нужно только для того, чтобы 5-10 минут поиграться со скриптами, эмулирующими различные проблемы в кластере, и посмотреть на изменения в графиках.
Мне кажется, что для этого же эффекта достаточно было дать доступ к заранее настроенному DataDog и/или продемонстрировать это всё со сцены, а это время потратить например на более подробный обзор и примеры использования того же Chaos Monkey, про который было просто рассказано буквально пару фраз.


Интересное: на этой конференции докладчики достаточно часто упоминали термин “blast radius”, который до этого мне не встречался. Им обозначали часть системы, которая оказывается задета при возникновании конкретной проблемы.
Дополнительные материалы:
- Chaos Engineering: The History, Principles, and Practice
- Chaos Monkey Guide for Engineers
- Репозиторий со скриптами для эмуляции проблем в системе (скрипты использовались в мастер-классе и там же есть ссылки на презентацию с аналогичного мастер-класса)
- Chaos Engineering Monitoring & Metrics Guide
- Planning Your Own Chaos Day
Building evolutionary infrastructure
| Ведущий: Kief Morris, консультант по инфраструктуре и автор книги “Infrastructure as a code” | Описание |
Основные тезисы мастер-класса можно свести к двум вещам:
- Системы всё время меняются, поэтому нормально, что инфраструктура тоже должна меняться;
- Раз инфраструктура меняется, то нужно добиться, чтобы это было просто и безопасно, а добиться этого можно только автоматизацией.
Основная часть его рассказа была посвящена именно автоматизации изменения инфраструктуры, возможным вариантам решения этой проблемы и тестированию изменений. Я не специалист в этой теме, но мне показалось, что он рассказывал про эту тему очень уверенно и подробно (и очень быстро).
Основной момент, который мне запомнился из этого мастер-класса — рекомендация максимально выносить различия между средами (продакшен, стейджинг и т.д.) из кода в переменные окружения. Это уменьшит вероятность возникнования ошибок в инфраструктуре при смене среды и сделает её более тестируемой.


Доклады
1 и 2 ноября было два дня докладов. Они были разбиты два принципиальных блока - серия из трёх или четырёх коротких keynote докладов, которые шли с утра в один поток (и для них собирался большой зал из двух меньших по размеру) и более длинные тематические доклады в 5 потоков, которые шли весь остальной день. В течение дня было несколько больших пауз между докладами, когда можно было погулять по экспо со стендами партнёров конференции.
Evolution of Runtastic Backend
| Simon Lasselsberger (Runtastic GmbH) | Описание и слайды |
Один из немногих докладов, в которых автор не просто рассказывал, как что-то нужно делать, а показывал детали конкретного проекта и что с ним проиходило.
В начале у Runtastic была общая база данных Percona Server и монолит с кодом, обслуживающим мобильные приложения и сайт. Потом они стали писать в Cassandra (не помню, по какой причине именно в неё) часть данных, для которых было достаточно key-value хранилища. Постепенно база пухла и они добавили MongoDB, в который стали писать данные из большинства сервисов. Со временем они сделали общий уровень, который обслуживает запросы и от web, и от мобильные приложения (что-то вроде нашей апификации, насколько я понял).
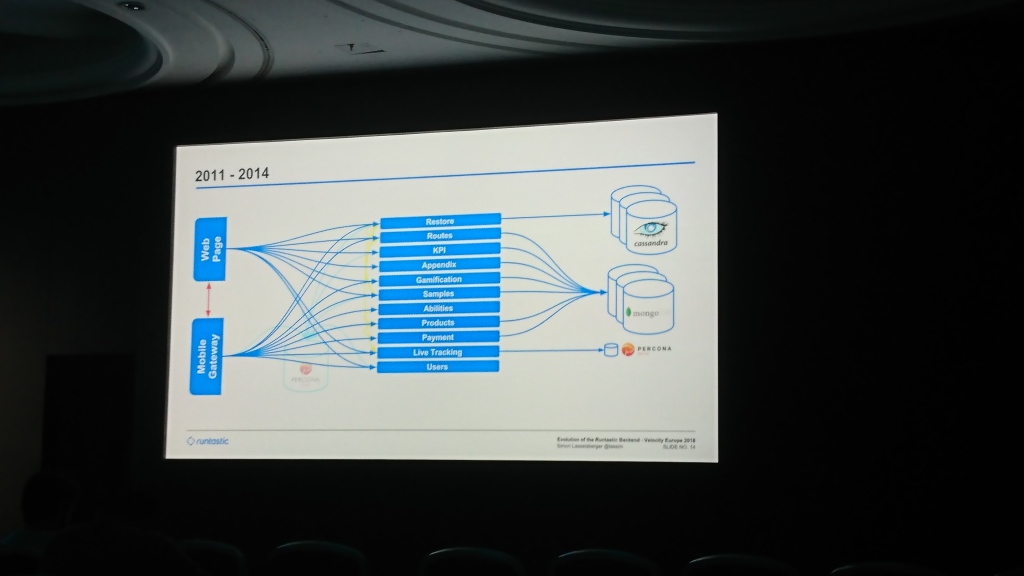
Большая часть доклада была посвящена переездам между дата-центрами. Сначала они держали сервера в Hetzner, который через какое-то время посчитали недостаточно стабильным и смигрировали данные в T-Systems. А еще через несколько лет они столкнулись с нехваткой места уже там и переехали еще раз в Linz AG. Самая интересная часть тут - это миграция данных. Они запустили копирование данных, которое длилось несколько месяцев. Они не могли столько ждать, т.к. у них заканчивалось место и они не могли его добавить, поэтому они сделали в коде fallback, который пытался читать данные из старого дата-центра в случае, если не их не было в новом.
В будущем они планируют разделить данные на несколько отдельных дата-центров (Симон несколько раз говорил, что это нужно для России и Китая) и жестко разделить базы данных по отдельным сервисам (сейчас используется общий пул на все сервисы).
Любопытный подход к проектированию модулей в системе, про который Симон вкользь упоминал: hexagonal architecture.
Allow an application to equally be driven by users, programs, automated test or batch scripts, and to be developed and tested in isolation from its eventual run-time devices and databases.
Alistair Cockburn
Дополнительные материалы:
Monitoring custom metrics; or, How I learned to instrument first and ask questions later
| Maxime Petazzoni (SignalFx) | Описание и презентация |
Рассказ был посвящён сбору метрик, необходимых для понимания работы приложения. Основной посыл заключался в том, что обычных RED-метрик (Rate, Errors, and Duration) совершенно не достаточно и кроме них нужно сразу собирать и другие, которые помогут понимать, что происходит внутри приложения.
Тезисно автор предлагал собирать каунтеры и таймеры для каких-то важных действий в системе (и обязательно счётчики отказов), строить по ним графики и гистограммы распределения, определить мета-модель для пользовательских метрик (чтобы у разных метрик был один и тот же набор обязательных параметров и одни и те же значения везде называли одинаково).

Словами пересказывать детали достаточно тяжело, проще будет посмотреть подробности и примеры в презентации, ссылка на которую есть на странице доклада на сайте конференции.
Дополнительные материалы:
How serverless changes the IT department
| Paul Johnston (Roundabout Labs) | Описание и презентация |
Автор представился как CTO и environmentalist, рассказал, что serverless — это не технологическое, а бизнес решение (“You pay nothing if it’s unused”). Потом описал best practices для работы с serverless, какие компетенции нужны для работы с ним и как это влияет на выбор новых сотрудников и работу с уже имеющимися.

Ключевым моментом “влияния на IT-департамент”, который я звпомил, было смещение необходимых компетенций от просто написания кода к работе с инфраструктурой и её автоматизацией (“More “engineering” than “developing”). Всё остальное было довольно банально (нужно постоянно проводить code review, документировать потоки данных и события, доступные для использования в системе, больше общаться и быстро учиться), но почему-то автор относил их к особенностям именно serverless.

В целом доклад показался немного неоднозначным. Многие вещи, про которые он говорил, можно отнести к любой сложной системе, которая не помещается в голову целиком.
Дополнительные материалы:
- Serverless Best Practices - статья автора c раскрытием best practices
Don’t panic! How to cope now that you’re responsible for production
| Euan Finlay (Financial Times) | Описание и презентация |
Доклад о том, как разбираться с инцидентами на продакшене, если прямо сейчас что-то идёт не так. Основные тезисы были разбиты на части по времени.
До инцидента:
- разграничьте алерты по критичности - возможно какие-то могут подождать и с ними не нужно срочно разбираться;
- заранее подготовьте план для разбора инцидентов и поддерживайте документацию в актуальном состоянии;
- проводите учения - ломайте что-то и смотрите, что происходит (aka chaos engineering);
- заведите единое место, куда стекается вся информация о изменениях и проблемах.
Во время инцидента:
- это нормально, что вы не знаете всего - привлекайте других людей, если это необходимо;
- заведите единое место для общения людей, работающих над решением инцидента;
- ищите максимально простое решение, которое вернёт продакшен в рабочее состояние, а не пытайтесь полнстью решить проблему.
После инцидента:
- разберитесь почему возникла проблема и чему это вас научило;
- важно написать отчёт об этом (“incident report”);
- определите, что может быть улучшено, и запланируйте конкретные действия.
В конце Юэн рассказал забавную историю инцидента в Financial Times, который возник из-за того, что по ошибке была модифицирована продакшен база (которая называлась prod) вместо предпродакшен (pprod), и посоветовал избегать настолько похожих названий.
Learning from the web of life (Keynote)
| Claire Janisch (BiomimicrySA) | Описание |
На этот доклад я опоздал, но в Твиттере про него очень хорошо отзывались. Нужно посмотреть, если попадётся.
Видео с фрагментом выступления можно посмотреть на сайте конференции.
The Misinformation Age (Keynote)
| Jane Adams (Two Sigma Investments) | Описание |
Философский доклад на тему “можем ли мы доверять алгоритмам принятие решений”. Общий вывод был, что нет: алгоритм может оптимизировать конкретные метрики, но при этом серьёзно влиять на то, что сложно измерить или лежит за пределами этих метрик (в качестве примера была дискриминация в алгоритме найма сотрудников в Amazon, что отрицательно влияло на культуру в компании и заставило отказаться от этого алгоритма).
The Freedom of Kubernetes (Keynote)
| Kris Nova | Описание |
Я оттуда запомнил две мысли:
- гибкость - это не свобода, а хаос;
- сложность сама по себе не проблема, если она несёт какую-то ценность (в оригинале это называлось “necessary complexity”), которая превышает стоимость этой сложности.
Доклад был достаточно философский поэтому, с одной стороны, у меня не получилось вынести из него много, но с другой то, что всё-таки вынес, применимо не только в Kubernetes.

What changes when we go offline-first? (Keynote)
| Martin Kleppmann (University of Cambridge), автор книги “Designing Data-Intensive Applications” | Описание |
Доклад состоял из двух логических частей: в первой Мартин рассказал о проблеме синхронизации между собой данных, которые могут изменяться в нескольких источниках независимо друг от друга, а во второй рассказал про вожможные варианты решений и алгоритмы, которые можно для этого использовать (operational transformation, OT, и conflict-free replicated data type, CRDT)) и предложил своё решение - библиотеку automerge для разрешения таких проблем.
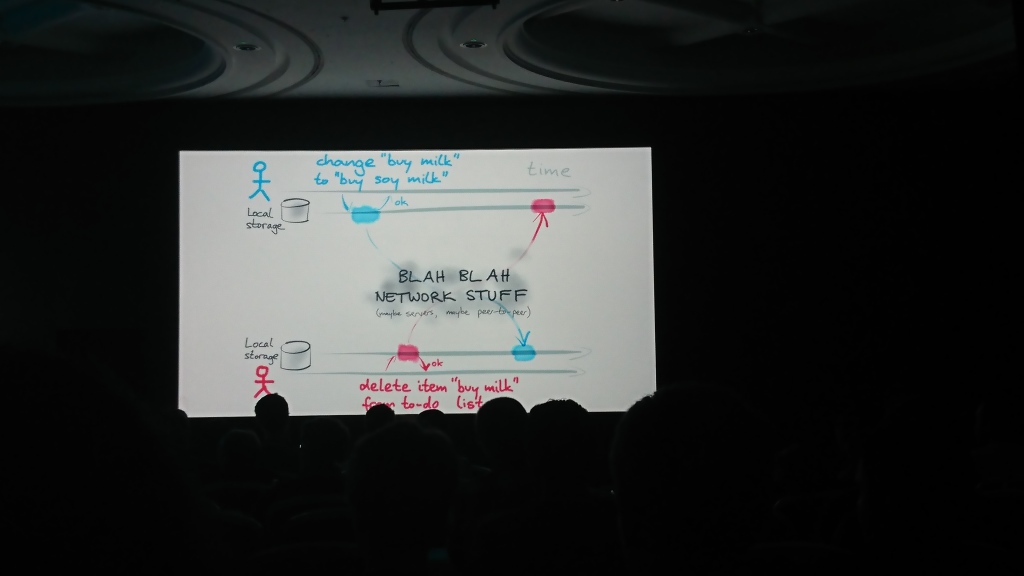


Дополнительные материалы:
A programmer’s guide to secure connections
| Докладчик: Liz Rice | Описание и слайды |
Доклад проходил в виде live coding сессии и в нём Лиз показала, как работает HTTPS, какие ошибки могут возникать при работе с защищёнными соединениями и как их решать. Каких-то больших глубин там не было, но сама демонстрация была очень хорошая.
Самое полезное: слайд с основными ошибками (он же с доклада Лиз на другой конференции):

Дополнительные материалы:
Everything you wanted to know about monorepos but were afraid to ask
| Simon Stewart (Selenium Project) | Описание |
Основной тезис доклада - в монорепо гораздо проще управлять зависимостями в коде и это перекрывает все плюсы отдельных репозиториев. Аппелировал к тому, что Google и Microsoft хранят даные в одном репозитории (размерами 86 Tb и 300 Gb соответственно), а репозиторий Facebook (54 Gb файлов) использует “off the shell mercurial”.
Зал “взорвался” после вопроса “У кого в компании репозиториев больше чем сотрудников?”
Аргумент “с большим репозиторием медленно работать” разбивал следующим образом:
- вам не обязательно забирать на локальную машину всю историю изменений: используйте shadow clone и sparse checkout;
- вам не обязательно использовать все файлы из репозитория: организуйте иерархию файлов и работайте только с нужной директорией, а всё остальное исключайте.
Дополнительные материалы:
Building a distributed real-time stream processing system
| Amy Boyle (New Relic) | Описание и презентация |
Хороший рассказ про работу с потоковыми данными от инженера из NewRelic (где у них явно много опыта по работе с такими данными). Эми рассказала что собой представляет работа с потоковыми данными, как их можно агрегировать, что можно делать с запаздывающими данными, как можно шардировать потоки событий и как их перебалансировать при отказах обработчиков, что мониторить и т.д.
В докладе было очень много материала, не буду пытаться его пересказать, а просто порекомендую посмотреть саму презентацию (она уже есть на сайте конференции).


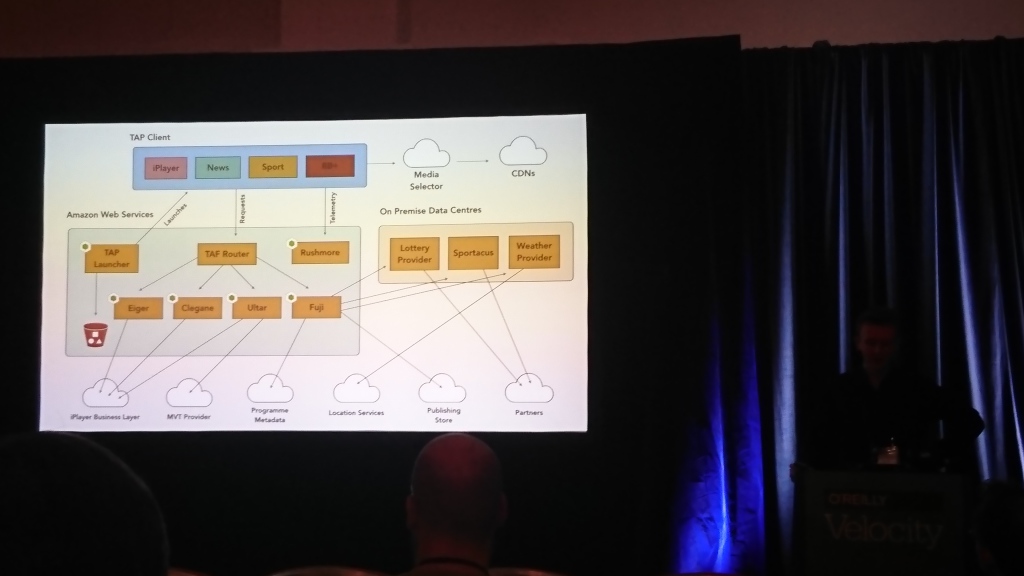
Architecting for TV
| David Buckhurst (BBC), Ross Wilson (BBC) | Описание |
Большая часть доклада была посвящена фронтэнду BBC. У ребят есть интерактивное телевидение и много телевизоров и других устройств (компьютеров, телефонов, планшетов), на которых это должно работать. С разными устройствами нужно работать совершенно по-разному, поэтому они придудали свой язык на базе JSON для описания интерфейсов и транслируют его в то, что умеет понимать конкретное устройство.
Основной вывод для меня — по сравнению с телевизионщиками у мобильных приложений нет никаких проблем со старыми клиентами.